การวิเคราะห์ข้อมูลเบื้องต้น (Introduction to Data Analysis)
Contents

การวิเคราะห์ข้อมูลเบื้องต้น (Introduction to Data Analysis)#
30 minutes
วัตถุประสงค์
หลังจากทำทำแล็บ นศ.จะสามารถ
วิเคราะห์ข้อมูลและแสดงผลโดยใช้ Pandas เบื้องต้นได้
Ref:
http://pandas.pydata.org/pandas-docs/stable/getting_started/index.html
https://www.kaggle.com/leonardodata/analysis-from-2010-2019-spotify
Dataset#
ตอนนี้ในมือของคุณมีชุดข้อมูล (Dataset) เพลง เป็นข้อมูลเพลงฮิตในแต่ละปีตั้งแต่ปี 2010 ถึงปี 2019 โดยข้อมูลอยู่ในรูปแบบของตาราง แต่ละแถว (row) ในตารางเป็นข้อมูลของเพลงแต่ละเพลง และแต่ละคอลัมน์ (column) มีข้อมูลดังต่อไปนี้
artist - ชื่อศิลปิน (นักร้อง วงดนตรี)
Top genre คือแนวเพลงหรือประเภทของแนวดนตรี
Year คือปีของเพลงที่อยู่ในบิลบอร์ด (Billboard)
Bpm (Tempo) คือจังหวะเร็วช้าขนาดไหน หน่วยเป็น bpm (Beats.Per.Minute)
Nrgy (Energy) คือพลังหรือความพุ่งของเพลง
Dnce (Danceability) คือความดิ้น หรือความน่าเต้นของเพลง
dB (Loudness) คือระดับความดังในหน่วย decibel
Live (Liveness) คือระดับของการแสดงสด (Live) ของเพลง
Val (Valence) คือระดับความ positive ในเพลง (ค่าต่ำ: เศร้า-หดหู่-โกรธ,คาสูง: มีความสุข-ให้กำลังใจ)
Dur (Length) - คือความยาว (ระยะเวลา) ของเพลง/ดนตรี
Acous (Acousticness) คือความ “acoustic” ของเพลง
Spch (Speechiness) คือปริมาณของคำพูดหรือเนื้อร้อง
Popularity คือระดับความนิยม ยิ่งค่าสูงเท่าไหร่ ยิ่งเป็นที่นิยม
ชุดข้อมูลที่ได้รับอยู่ในรูปตาราง (Format CSV)
(Source: spotifycharts.com, kaggle.com)
# |
title |
artist |
top genre |
year |
bpm |
nrgy |
dnce |
dB |
live |
val |
dur |
acous |
spch |
pop |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
1 |
Memories |
Maroon 5 |
pop |
2019 |
91 |
32 |
76 |
-7 |
8 |
57 |
189 |
84 |
5 |
99 |
2 |
Lose You To Love Me |
Selena Gomez |
dance pop |
2019 |
102 |
34 |
51 |
-9 |
21 |
9 |
206 |
58 |
4 |
97 |
3 |
Someone You Loved |
Lewis Capaldi |
pop |
2019 |
110 |
41 |
50 |
-6 |
11 |
45 |
182 |
75 |
3 |
96 |
4 |
Senorita |
Shawn Mendes |
canadian pop |
2019 |
117 |
54 |
76 |
-6 |
9 |
75 |
191 |
4 |
3 |
95 |
5 |
How Do You Sleep? |
Sam Smith |
pop |
2019 |
111 |
68 |
48 |
-5 |
8 |
35 |
202 |
15 |
9 |
93 |
6 |
South of the Border (feat. Camila Cabello & Cardi B) |
Ed Sheeran |
pop |
2019 |
98 |
62 |
86 |
-6 |
9 |
67 |
204 |
15 |
8 |
92 |
7 |
Trampoline (with ZAYN) |
SHAED |
electropop |
2019 |
127 |
46 |
62 |
-6 |
14 |
50 |
184 |
56 |
3 |
92 |
8 |
Happier |
Marshmello |
brostep |
2019 |
100 |
79 |
69 |
-3 |
17 |
67 |
214 |
19 |
5 |
90 |
9 |
Truth Hurts |
Lizzo |
escape room |
2019 |
158 |
62 |
72 |
-3 |
12 |
41 |
173 |
11 |
11 |
90 |
10 |
Good as Hell (feat. Ariana Grande) - Remix |
Lizzo |
escape room |
2019 |
96 |
89 |
67 |
-3 |
74 |
48 |
159 |
30 |
6 |
90 |
11 |
Underneath the Tree |
Kelly Clarkson |
dance pop |
2013 |
160 |
81 |
51 |
-5 |
21 |
69 |
230 |
0 |
5 |
88 |
12 |
Higher Love |
Kygo |
edm |
2019 |
104 |
68 |
69 |
-7 |
10 |
40 |
228 |
2 |
3 |
88 |
13 |
Shape of You |
Ed Sheeran |
pop |
2017 |
96 |
65 |
83 |
-3 |
9 |
93 |
234 |
58 |
8 |
87 |
14 |
Only Human |
Jonas Brothers |
boy band |
2019 |
94 |
50 |
80 |
-6 |
6 |
87 |
183 |
11 |
7 |
87 |
15 |
All of Me |
John Legend |
neo mellow |
2014 |
120 |
26 |
42 |
-7 |
13 |
33 |
270 |
92 |
3 |
86 |
16 |
Closer |
The Chainsmokers |
electropop |
2017 |
95 |
52 |
75 |
-6 |
11 |
66 |
245 |
41 |
3 |
86 |
17 |
One Kiss (with Dua Lipa) |
Calvin Harris |
dance pop |
2018 |
124 |
86 |
79 |
-3 |
8 |
59 |
215 |
4 |
11 |
86 |
18 |
Beautiful People (feat. Khalid) |
Ed Sheeran |
pop |
2019 |
93 |
65 |
64 |
-8 |
8 |
55 |
198 |
12 |
19 |
86 |
19 |
Sucker |
Jonas Brothers |
boy band |
2019 |
138 |
73 |
84 |
-5 |
11 |
95 |
181 |
4 |
6 |
86 |
20 |
Don’t Call Me Up |
Mabel |
dance pop |
2019 |
99 |
88 |
67 |
-3 |
8 |
23 |
178 |
30 |
15 |
86 |
Pandas คือ ?#
Pandas* เป็นไลบรารี่ที่ได้รับความนิยมอย่างมากอันหนึ่งของภาษาไพทอน ใช้ในการจัดการข้อมูล (Data wrangling/ Data cleaning) และการวิเคราะห์ข้อมูล (Data analysis) สามารถจัดการกับข้อมูลที่มีขนาดใหญ่ๆ ได้โดยที่ไม่มีปัญหา (ในขณะที่โปรแกรม Spreadsheets อย่าง Excel มีปัญหาเรื่องการประมวลผลช้าและไม่เสถียร)
เนื่องจาก Pandas ไม่ใช่โมดูลมาตรฐานของไพทอน ดังนั้น ก่อนจะใช้งานจำเป็นต้องติดตั้งลงเครื่องก่อน (pip install หรือ conda install)
เราจะเริ่มต้นเขียนโปรแกรมโดยการ import เข้ามา ณ ที่นี้จะตั้งชื่อว่า pd เพื่อให้เวลาเรียกใช้งานฟังก์ชันจะได้เขียนง่ายๆ เช่น pd.read_csv()
(*Pandas มาจาก Panel data ซึ่งหมายถึงข้อมูลที่มีหลายมิติ)
Import ไลบรารี่ที่จะใช้งาน#
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#import matplotlib as mpl
%matplotlib inline
โหลดชุดข้อมูลไฟล์ CSV เข้าสู่โปรแกรมในรูปแบบ DataFrame
The top songs BY YEAR in the world by spotify. This dataset has several variables about the songs and is based on Billboard.
(ชุดข้อมูลข้างต้นสามารถดาวโหลดได้จาก spotifycharts.com หรือ kaggle.com โดยข้อมูลดิบจะเรียงตามปี (Year) ในรูปของไฟล์ CSV (Comma-Separated Values) )
ก่อนอื่น เราจะโหลดไฟล์ข้อมูล csv ที่อยู่ในเครื่องของเราเข้าสู่ไพทอนในรูปแบบ DataFrame (DataFrame คือ ตารางข้อมูลที่ถูกแบ่งเป็นแถวและคอลัมน์เหมือน Excel) โดยใช้ฟังก์ชัน read_csv()
ตัวแปร csv_path เก็บที่อยู่ของไฟล์ (path) .csv ส่งเป็นอาร์กิวเมนต์ให้กับฟังก์ชั่น read_csv ผลลัพธ์จะถูกเก็บในออบเจ็กต์ชื่อ df ซึ่งเป็นชื่อย่อของตัวแปรที่นิยมใช้เก็บ DataFrame
# Read data from CSV file
csv_path = 'docs/Top_Spotify_songs_from_2010_2019.csv'
df = pd.read_csv(csv_path, encoding='ISO-8859-1')
แสดงตัวอย่างข้อมูล (Preview) ของ Dataframe ได้โดยใช้ฟังก์ชัน ใช้เมธอด head()
# Print first five rows of the dataframe
df.head()
| Unnamed: 0 | title | artist | top genre | year | bpm | nrgy | dnce | dB | live | val | dur | acous | spch | pop | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | Hey, Soul Sister | Train | neo mellow | 2010 | 97 | 89 | 67 | -4 | 8 | 80 | 217 | 19 | 4 | 83 |
| 1 | 2 | Love The Way You Lie | Eminem | detroit hip hop | 2010 | 87 | 93 | 75 | -5 | 52 | 64 | 263 | 24 | 23 | 82 |
| 2 | 3 | TiK ToK | Kesha | dance pop | 2010 | 120 | 84 | 76 | -3 | 29 | 71 | 200 | 10 | 14 | 80 |
| 3 | 4 | Bad Romance | Lady Gaga | dance pop | 2010 | 119 | 92 | 70 | -4 | 8 | 71 | 295 | 0 | 4 | 79 |
| 4 | 5 | Just the Way You Are | Bruno Mars | pop | 2010 | 109 | 84 | 64 | -5 | 9 | 43 | 221 | 2 | 4 | 78 |
ในกรณีที่ข้อมูลเป็นไฟล์ excel (.xlsx, .xls) Pandas จะใช้ไลบรารี xlrd โดยเรียกใช้ใช้ฟังก์ชั่น read_excel() ซึ่งผลลัพท์ที่ได้จะเป็น Dataframe เช่นเดียวกัน
ตัวอย่างการวิเคราะห์ข้อมูลเพลงฮิตสปอติฟายในช่วง 2010~2019#
Ref: https://www.kaggle.com/scratchpad/notebook42c2f8a089
จัดเตรียมชุดข้อมูล (Data preparation)#
จากข้อมูลที่ได้มา เราจะเปลี่ยนชื่อของคอลัมน์จาก top genres เป็น top_genres และลบคอลัมน์ไม่มีชื่อ (Unnamed: 0) ทิ้ง เพื่อหลีกเลี่ยงปัญหาที่อาจเกิดขึ้นได้ในภายหลัง
เนื่องจากชุดข้อมูลนี้ไม่มีช่องใดที่มีค่า NaN จึงพร้อมสำหรับการวิเคราะห์
df = df.rename(columns={'top genre': 'top_genre'})
df = df.drop('Unnamed: 0', axis=1)
print(df.columns)
Index(['title', 'artist', 'top_genre', 'year', 'bpm', 'nrgy', 'dnce', 'dB',
'live', 'val', 'dur', 'acous', 'spch', 'pop'],
dtype='object')
df.head()
| title | artist | top_genre | year | bpm | nrgy | dnce | dB | live | val | dur | acous | spch | pop | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Hey, Soul Sister | Train | neo mellow | 2010 | 97 | 89 | 67 | -4 | 8 | 80 | 217 | 19 | 4 | 83 |
| 1 | Love The Way You Lie | Eminem | detroit hip hop | 2010 | 87 | 93 | 75 | -5 | 52 | 64 | 263 | 24 | 23 | 82 |
| 2 | TiK ToK | Kesha | dance pop | 2010 | 120 | 84 | 76 | -3 | 29 | 71 | 200 | 10 | 14 | 80 |
| 3 | Bad Romance | Lady Gaga | dance pop | 2010 | 119 | 92 | 70 | -4 | 8 | 71 | 295 | 0 | 4 | 79 |
| 4 | Just the Way You Are | Bruno Mars | pop | 2010 | 109 | 84 | 64 | -5 | 9 | 43 | 221 | 2 | 4 | 78 |
ตรวจสอบความสัมพันธ์ของแต่ละฟีเจอร์ (Features) ในชุดข้อมูล#
df.corr() # corr() is used to find the pairwise correlation of all columns in the dataframe.
/var/folders/nb/qx4_7k_n2mx3zzwh39qtrg_c0000gn/T/ipykernel_82260/2964105268.py:1: FutureWarning: The default value of numeric_only in DataFrame.corr is deprecated. In a future version, it will default to False. Select only valid columns or specify the value of numeric_only to silence this warning.
df.corr() # corr() is used to find the pairwise correlation of all columns in the dataframe.
| year | bpm | nrgy | dnce | dB | live | val | dur | acous | spch | pop | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| year | 1.000000 | -0.104247 | -0.225596 | 0.079269 | -0.126471 | -0.136331 | -0.122025 | -0.215344 | 0.101725 | 0.004778 | 0.241261 |
| bpm | -0.104247 | 1.000000 | 0.126170 | -0.131301 | 0.183870 | 0.081579 | 0.016021 | -0.029359 | -0.113257 | 0.058999 | 0.018983 |
| nrgy | -0.225596 | 0.126170 | 1.000000 | 0.167209 | 0.537528 | 0.186738 | 0.409577 | -0.143610 | -0.562287 | 0.107313 | -0.057645 |
| dnce | 0.079269 | -0.131301 | 0.167209 | 1.000000 | 0.233170 | -0.028801 | 0.501696 | -0.176841 | -0.240064 | -0.028041 | 0.116054 |
| dB | -0.126471 | 0.183870 | 0.537528 | 0.233170 | 1.000000 | 0.081934 | 0.282922 | -0.104723 | -0.190401 | -0.001110 | 0.156897 |
| live | -0.136331 | 0.081579 | 0.186738 | -0.028801 | 0.081934 | 1.000000 | 0.020226 | 0.098339 | -0.098167 | 0.144103 | -0.075749 |
| val | -0.122025 | 0.016021 | 0.409577 | 0.501696 | 0.282922 | 0.020226 | 1.000000 | -0.262256 | -0.249038 | 0.122013 | 0.038953 |
| dur | -0.215344 | -0.029359 | -0.143610 | -0.176841 | -0.104723 | 0.098339 | -0.262256 | 1.000000 | 0.091802 | 0.054564 | -0.104363 |
| acous | 0.101725 | -0.113257 | -0.562287 | -0.240064 | -0.190401 | -0.098167 | -0.249038 | 0.091802 | 1.000000 | 0.002763 | 0.026704 |
| spch | 0.004778 | 0.058999 | 0.107313 | -0.028041 | -0.001110 | 0.144103 | 0.122013 | 0.054564 | 0.002763 | 1.000000 | -0.041490 |
| pop | 0.241261 | 0.018983 | -0.057645 | 0.116054 | 0.156897 | -0.075749 | 0.038953 | -0.104363 | 0.026704 | -0.041490 | 1.000000 |
พล็อตข้อมูลตรวจสอบความสัมพันธ์กันระหว่างข้อมูล#
พล็อต Heatmap ด้วย Seaborn
import seaborn as sn
plt.figure(figsize=(8, 7))
sn.heatmap(df.corr(),
annot = True,
fmt = '.2f',
cmap='Blues')
plt.title('Correlation between variables in the Spotify data set')
plt.show()
/var/folders/nb/qx4_7k_n2mx3zzwh39qtrg_c0000gn/T/ipykernel_82260/4252206390.py:2: FutureWarning: The default value of numeric_only in DataFrame.corr is deprecated. In a future version, it will default to False. Select only valid columns or specify the value of numeric_only to silence this warning.
sn.heatmap(df.corr(),
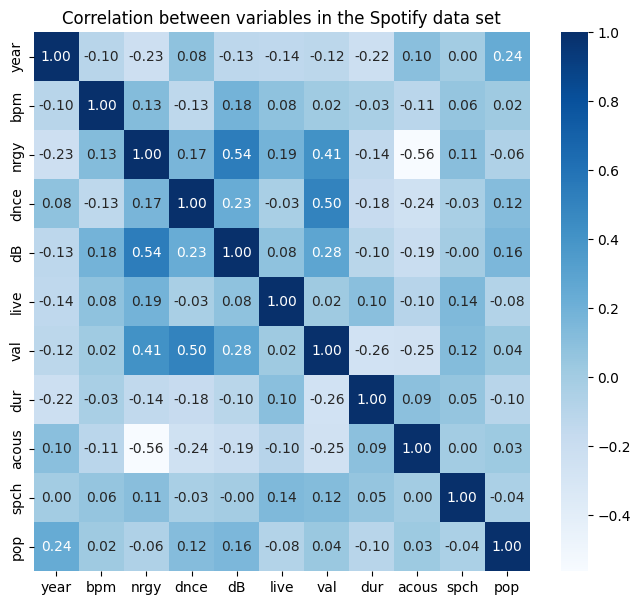
จากแผนภูมิข้างต้น เราพบฟีเจอร์ (Features) ที่มีความสัมพันธ์กัน
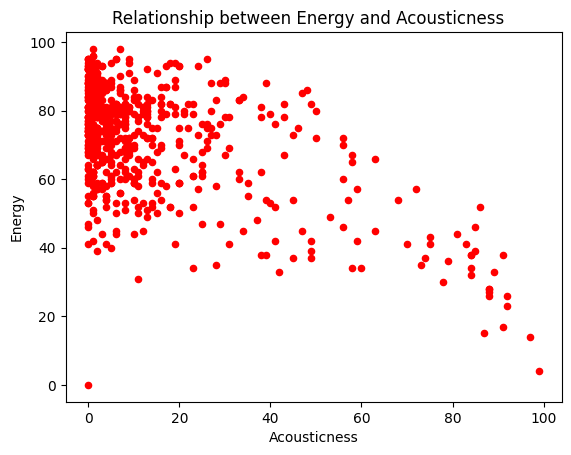
-> Acous กับ NRGY -0.56
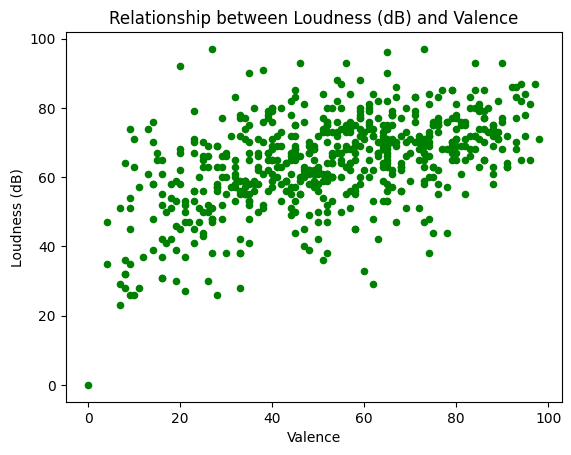
-> Val กับ DNCE 0.50
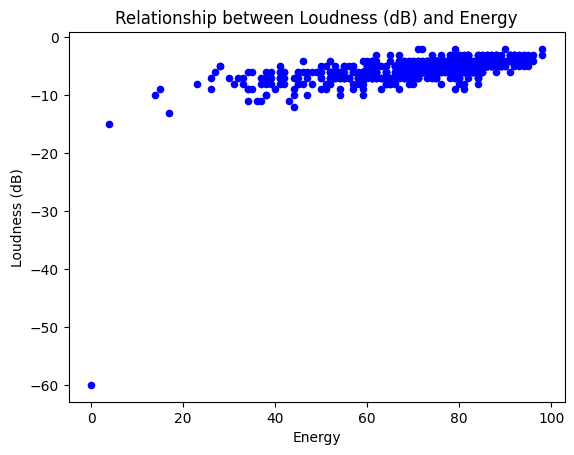
-> dB กับ NRGY 0.54
พล็อตข้อมูลที่มีความสัมพันธ์กัน
Top genre คือแนวเพลงหรือประเภทของแนวดนตรี
Year คือปีของเพลงที่อยู่ในบิลบอร์ด (Billboard)
Bpm (Tempo) คือจังหวะเร็วช้าขนาดไหน หน่วยเป็น bpm (Beats.Per.Minute)
Nrgy (Energy) คือพลังหรือความพุ่งของเพลง
Dnce (Danceability) คือความดิ้น หรือความน่าเต้นของเพลง
dB (Loudness) คือระดับความดังในหน่วย decibel
Live (Liveness) คือระดับของการแสดงสด (Live) ของเพลง
Val (Valence) คือระดับความ positive ในเพลง (ค่าต่ำ: เศร้า-หดหู่-โกรธ,ค่าสูง: มีความสุข-ให้กำลังใจ)
Dur (Length) - คือความยาว (ระยะเวลา) ของเพลง/ดนตรี
Acous (Acousticness) คือความ “acoustic” ของเพลง
Spch (Speechiness) คือปริมาณของคำพูดหรือเนื้อร้อง
Popularity คือระดับความนิยม ยิ่งค่าสูงเท่าไหร่ ยิ่งเป็นที่นิยม
df.plot(x='acous',y='nrgy',kind='scatter', title='Relationship between Energy and Acousticness ',color='r')
plt.xlabel('Acousticness')
plt.ylabel('Energy')
df.plot(x='nrgy',y='dB',kind='scatter', title='Relationship between Loudness (dB) and Energy',color='b')
plt.xlabel('Energy')
plt.ylabel('Loudness (dB)')
df.plot(x='val',y='dnce',kind='scatter', title='Relationship between Loudness (dB) and Valence',color='g')
plt.xlabel('Valence')
plt.ylabel('Loudness (dB)')
Text(0, 0.5, 'Loudness (dB)')
วิเคราะห์ชุดข้อมูล#
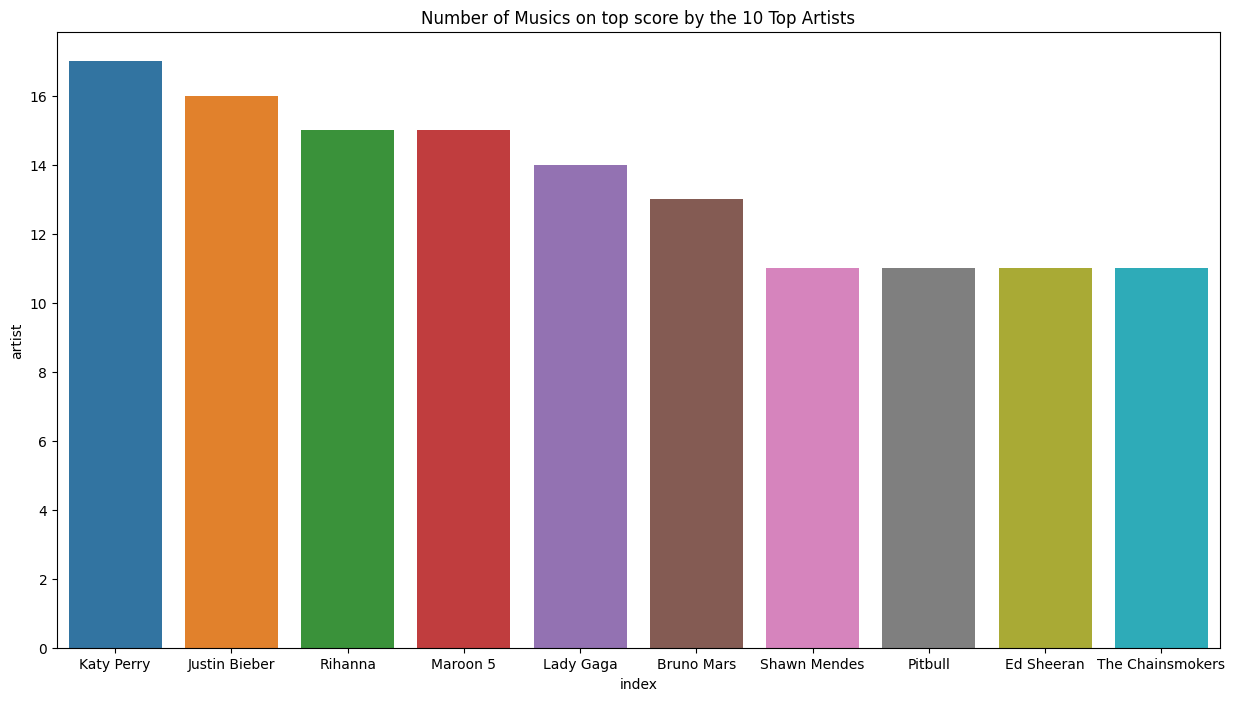
ศิลปินที่มีจำนวนเพลงมาก 10 อันดับแรก?#
artists = df['artist'].unique() # Return unique values of Series object. Uniques are returned in order of appearance
print("The dfset has {} artists".format (len(artists)))
print(type(artists))
artists[0:10]
The dfset has 184 artists
<class 'numpy.ndarray'>
array(['Train', 'Eminem', 'Kesha', 'Lady Gaga', 'Bruno Mars',
'Justin Bieber', 'Taio Cruz', 'OneRepublic', 'Alicia Keys',
'Rihanna'], dtype=object)
# ดูความถี่ของค่าในคอลัมน์ต่างๆ กรณี 'artist'
df['artist'].value_counts() # Type: pandas.core.series.Series
Katy Perry 17
Justin Bieber 16
Rihanna 15
Maroon 5 15
Lady Gaga 14
..
Iggy Azalea 1
5 Seconds of Summer 1
Michael Jackson 1
Disclosure 1
Daddy Yankee 1
Name: artist, Length: 184, dtype: int64
# value_counts() function return a Series containing counts of unique values.
# reset_index() resets the index of the DataFrame, and use the default one instead.
artists = df['artist'].value_counts().reset_index().head(10)
print(type(artists))
print(artists)
<class 'pandas.core.frame.DataFrame'>
index artist
0 Katy Perry 17
1 Justin Bieber 16
2 Rihanna 15
3 Maroon 5 15
4 Lady Gaga 14
5 Bruno Mars 13
6 Shawn Mendes 11
7 Pitbull 11
8 Ed Sheeran 11
9 The Chainsmokers 11
plt.figure(figsize=(15,8))
sn.barplot(x='index',y='artist', data=artists)
plt.title("Number of Musics on top score by the 10 Top Artists")
Text(0.5, 1.0, 'Number of Musics on top score by the 10 Top Artists')
เพลงที่มีชื่อในชุดข้อมูลมากกว่าหนึ่งครั้ง#
df['title'].value_counts().head(20)>1
A Little Party Never Killed Nobody (All We Got) True
All I Ask True
Kissing Strangers True
Written in the Stars (feat. Eric Turner) True
The Hills True
Love Yourself True
We Are Never Ever Getting Back Together True
Sugar True
Say Something True
First Time True
Stitches True
I Like It True
Hello True
Castle Walls (feat. Christina Aguilera) True
Company True
Runnin' (Lose It All) True
Marry You True
Just the Way You Are True
Here True
Ain't Your Mama False
Name: title, dtype: bool
ดูข้อมูลของเพลงทุกเพลงที่ซ้ำ
more_than_one = df['title'].value_counts().head(19)
more_than_one
A Little Party Never Killed Nobody (All We Got) 2
All I Ask 2
Kissing Strangers 2
Written in the Stars (feat. Eric Turner) 2
The Hills 2
Love Yourself 2
We Are Never Ever Getting Back Together 2
Sugar 2
Say Something 2
First Time 2
Stitches 2
I Like It 2
Hello 2
Castle Walls (feat. Christina Aguilera) 2
Company 2
Runnin' (Lose It All) 2
Marry You 2
Just the Way You Are 2
Here 2
Name: title, dtype: int64
การวิเคราะห์โดยการเรียงลำดับข้อมูล#
เพลงที่มีระดับความนิยม (Popularity) มากสุด Top 15#
จากข้อมูลสรุปได้ว่า เพลงฮิตมากที่สุดแทบทุกเพลงเป็นเพลงในปี 2019
df.sort_values(by=['pop'], ascending=False).head(15)
| title | artist | top_genre | year | bpm | nrgy | dnce | dB | live | val | dur | acous | spch | pop | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 572 | Memories | Maroon 5 | pop | 2019 | 91 | 32 | 76 | -7 | 8 | 57 | 189 | 84 | 5 | 99 |
| 573 | Lose You To Love Me | Selena Gomez | dance pop | 2019 | 102 | 34 | 51 | -9 | 21 | 9 | 206 | 58 | 4 | 97 |
| 574 | Someone You Loved | Lewis Capaldi | pop | 2019 | 110 | 41 | 50 | -6 | 11 | 45 | 182 | 75 | 3 | 96 |
| 575 | Señorita | Shawn Mendes | canadian pop | 2019 | 117 | 54 | 76 | -6 | 9 | 75 | 191 | 4 | 3 | 95 |
| 576 | How Do You Sleep? | Sam Smith | pop | 2019 | 111 | 68 | 48 | -5 | 8 | 35 | 202 | 15 | 9 | 93 |
| 578 | Trampoline (with ZAYN) | SHAED | electropop | 2019 | 127 | 46 | 62 | -6 | 14 | 50 | 184 | 56 | 3 | 92 |
| 577 | South of the Border (feat. Camila Cabello & Ca... | Ed Sheeran | pop | 2019 | 98 | 62 | 86 | -6 | 9 | 67 | 204 | 15 | 8 | 92 |
| 580 | Truth Hurts | Lizzo | escape room | 2019 | 158 | 62 | 72 | -3 | 12 | 41 | 173 | 11 | 11 | 90 |
| 581 | Good as Hell (feat. Ariana Grande) - Remix | Lizzo | escape room | 2019 | 96 | 89 | 67 | -3 | 74 | 48 | 159 | 30 | 6 | 90 |
| 579 | Happier | Marshmello | brostep | 2019 | 100 | 79 | 69 | -3 | 17 | 67 | 214 | 19 | 5 | 90 |
| 582 | Higher Love | Kygo | edm | 2019 | 104 | 68 | 69 | -7 | 10 | 40 | 228 | 2 | 3 | 88 |
| 139 | Underneath the Tree | Kelly Clarkson | dance pop | 2013 | 160 | 81 | 51 | -5 | 21 | 69 | 230 | 0 | 5 | 88 |
| 583 | Only Human | Jonas Brothers | boy band | 2019 | 94 | 50 | 80 | -6 | 6 | 87 | 183 | 11 | 7 | 87 |
| 443 | Shape of You | Ed Sheeran | pop | 2017 | 96 | 65 | 83 | -3 | 9 | 93 | 234 | 58 | 8 | 87 |
| 584 | Beautiful People (feat. Khalid) | Ed Sheeran | pop | 2019 | 93 | 65 | 64 | -8 | 8 | 55 | 198 | 12 | 19 | 86 |
เพลงที่มีความยาว (ระยะเวลา) มากสุด Top 15#
df.sort_values(by=['dur'], ascending=False).head(-5)
| title | artist | top_genre | year | bpm | nrgy | dnce | dB | live | val | dur | acous | spch | pop | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 188 | TKO | Justin Timberlake | dance pop | 2013 | 138 | 68 | 61 | -7 | 43 | 49 | 424 | 1 | 24 | 58 |
| 422 | Wish That You Were Here - From Miss Peregrine... | Florence + The Machine | art pop | 2016 | 94 | 57 | 37 | -6 | 13 | 12 | 403 | 72 | 3 | 57 |
| 63 | Monster | Kanye West | chicago rap | 2011 | 125 | 69 | 63 | -6 | 67 | 10 | 379 | 0 | 20 | 73 |
| 162 | Lose Yourself to Dance | Daft Punk | electro | 2013 | 100 | 66 | 83 | -8 | 8 | 67 | 354 | 8 | 6 | 72 |
| 194 | Take Back the Night | Justin Timberlake | dance pop | 2013 | 107 | 66 | 59 | -5 | 64 | 33 | 353 | 4 | 16 | 54 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 390 | Light It Up (feat. Nyla & Fuse ODG) [Remix] | Major Lazer | dance pop | 2016 | 108 | 88 | 75 | -4 | 23 | 75 | 166 | 4 | 7 | 73 |
| 547 | Nervous | Shawn Mendes | canadian pop | 2018 | 122 | 62 | 84 | -7 | 13 | 74 | 164 | 4 | 8 | 71 |
| 595 | Antisocial (with Travis Scott) | Ed Sheeran | pop | 2019 | 152 | 82 | 72 | -5 | 36 | 91 | 162 | 13 | 5 | 78 |
| 260 | Tee Shirt - Soundtrack Version | Birdy | neo mellow | 2014 | 76 | 34 | 68 | -9 | 9 | 56 | 160 | 84 | 3 | 49 |
| 334 | Reality - Radio Edit | Lost Frequencies | belgian edm | 2015 | 122 | 70 | 71 | -8 | 7 | 60 | 159 | 2 | 3 | 61 |
598 rows × 14 columns
เพลงที่มีความ “Acoustic” มากสุด Top 15#
df.sort_values(by=['acous'], ascending=False).head(5)
| title | artist | top_genre | year | bpm | nrgy | dnce | dB | live | val | dur | acous | spch | pop | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 431 | Start | John Legend | neo mellow | 2016 | 110 | 4 | 52 | -15 | 9 | 26 | 310 | 99 | 4 | 47 |
| 255 | Not About Angels | Birdy | neo mellow | 2014 | 116 | 14 | 41 | -10 | 9 | 23 | 190 | 97 | 4 | 56 |
| 186 | Clown | Emeli Sandé | dance pop | 2013 | 130 | 23 | 45 | -8 | 11 | 23 | 221 | 92 | 4 | 60 |
| 210 | All of Me | John Legend | neo mellow | 2014 | 120 | 26 | 42 | -7 | 13 | 33 | 270 | 92 | 3 | 86 |
| 96 | Turning Page | Sleeping At Last | acoustic pop | 2011 | 125 | 38 | 30 | -8 | 11 | 19 | 255 | 91 | 3 | 46 |
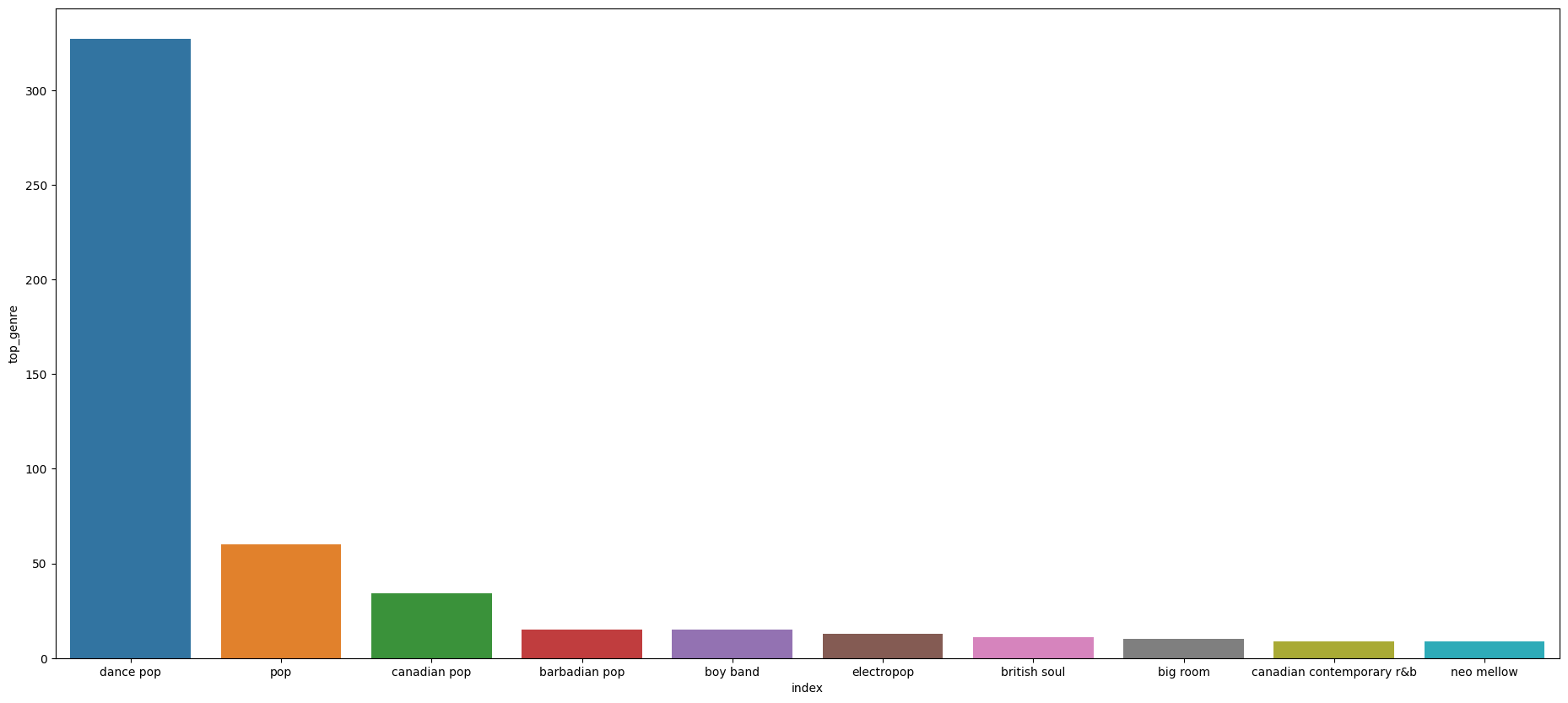
แนวเพลงประเภทไหนที่อยู่ในชุดข้อมูล 10 อันดับแรก?#
genres = df['top_genre'].value_counts().reset_index().head(10)
genres.head(10)
| index | top_genre | |
|---|---|---|
| 0 | dance pop | 327 |
| 1 | pop | 60 |
| 2 | canadian pop | 34 |
| 3 | barbadian pop | 15 |
| 4 | boy band | 15 |
| 5 | electropop | 13 |
| 6 | british soul | 11 |
| 7 | big room | 10 |
| 8 | canadian contemporary r&b | 9 |
| 9 | neo mellow | 9 |
plt.figure(figsize=(23,10))
sn.barplot(x='index',y='top_genre', data=genres)
<Axes: xlabel='index', ylabel='top_genre'>
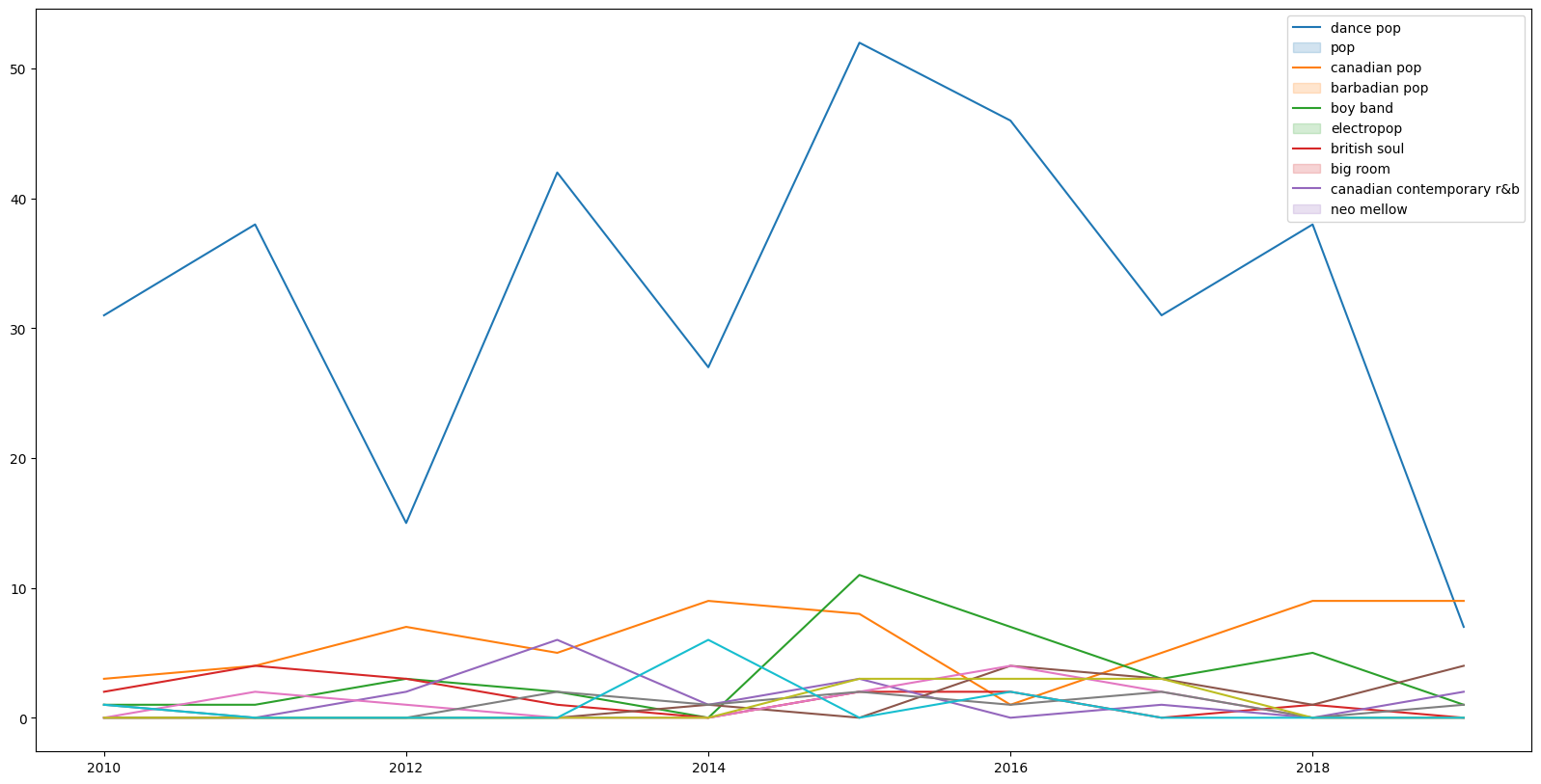
plt.figure(figsize=(20,10))
for i in genres['index']:
tmp = []
for y in range(2010,2020):
songs = df[df['year'] == y][df['top_genre'] == i]
tmp.append(songs.shape[0])
sn.lineplot(x=list(range(2010,2020)),y=tmp)
plt.legend(list(genres['index']))
/var/folders/nb/qx4_7k_n2mx3zzwh39qtrg_c0000gn/T/ipykernel_82260/1342248677.py:5: UserWarning: Boolean Series key will be reindexed to match DataFrame index.
songs = df[df['year'] == y][df['top_genre'] == i]
/var/folders/nb/qx4_7k_n2mx3zzwh39qtrg_c0000gn/T/ipykernel_82260/1342248677.py:5: UserWarning: Boolean Series key will be reindexed to match DataFrame index.
songs = df[df['year'] == y][df['top_genre'] == i]
/var/folders/nb/qx4_7k_n2mx3zzwh39qtrg_c0000gn/T/ipykernel_82260/1342248677.py:5: UserWarning: Boolean Series key will be reindexed to match DataFrame index.
songs = df[df['year'] == y][df['top_genre'] == i]
/var/folders/nb/qx4_7k_n2mx3zzwh39qtrg_c0000gn/T/ipykernel_82260/1342248677.py:5: UserWarning: Boolean Series key will be reindexed to match DataFrame index.
songs = df[df['year'] == y][df['top_genre'] == i]
/var/folders/nb/qx4_7k_n2mx3zzwh39qtrg_c0000gn/T/ipykernel_82260/1342248677.py:5: UserWarning: Boolean Series key will be reindexed to match DataFrame index.
songs = df[df['year'] == y][df['top_genre'] == i]
/var/folders/nb/qx4_7k_n2mx3zzwh39qtrg_c0000gn/T/ipykernel_82260/1342248677.py:5: UserWarning: Boolean Series key will be reindexed to match DataFrame index.
songs = df[df['year'] == y][df['top_genre'] == i]
/var/folders/nb/qx4_7k_n2mx3zzwh39qtrg_c0000gn/T/ipykernel_82260/1342248677.py:5: UserWarning: Boolean Series key will be reindexed to match DataFrame index.
songs = df[df['year'] == y][df['top_genre'] == i]
/var/folders/nb/qx4_7k_n2mx3zzwh39qtrg_c0000gn/T/ipykernel_82260/1342248677.py:5: UserWarning: Boolean Series key will be reindexed to match DataFrame index.
songs = df[df['year'] == y][df['top_genre'] == i]
/var/folders/nb/qx4_7k_n2mx3zzwh39qtrg_c0000gn/T/ipykernel_82260/1342248677.py:5: UserWarning: Boolean Series key will be reindexed to match DataFrame index.
songs = df[df['year'] == y][df['top_genre'] == i]
/var/folders/nb/qx4_7k_n2mx3zzwh39qtrg_c0000gn/T/ipykernel_82260/1342248677.py:5: UserWarning: Boolean Series key will be reindexed to match DataFrame index.
songs = df[df['year'] == y][df['top_genre'] == i]
<matplotlib.legend.Legend at 0x12f59b3d0>
Change Log#
Date |
Version |
Change Description |
|---|---|---|
08-08-2021 |
0.1 |
First edition |